Device-native AI: waarom het beste model soms niet in het datacenter draait

Kort antwoord: device-native AI is geen mini-cloudmodel
Device-native AI betekent dat een AI-model is ontworpen om op of dicht bij het apparaat van de gebruiker te draaien: een telefoon, laptop, auto, wearable of ander edge-apparaat. Het model is dan niet alleen kleiner dan een groot cloudmodel, maar ook afgestemd op beperkingen zoals geheugen, batterij, chiparchitectuur, verbindingskwaliteit en reactietijd. Dat maakt het een product- en infrastructuurkeuze, geen simpele modelkeuze.
Voor AI-teams is de relevante vraag daarom niet: kunnen we een groot model comprimeren? De betere vraag is: welke intelligentie hoort lokaal te draaien en welke intelligentie hoort centraal in de cloud? Bij sommige toepassingen is een cloud-LLM logisch omdat je veel context, zware redenering of snelle modelupdates nodig hebt. Bij andere toepassingen telt vooral directe respons, privacygevoelige invoer, offline beschikbaarheid of interactie met sensoren. Dan kan on-device AI aantrekkelijk zijn, mits je het nuchter evalueert.
De valkuil is dat on-device AI wordt verkocht als automatisch sneller, goedkoper of veiliger. Dat is te kort door de bocht. Lokaal draaien kan latency verminderen, maar alleen als model, hardware en productflow daarop zijn ingericht. Data kan lokaal blijven, maar privacy vraagt nog steeds om goed ontwerp, toestemming, loggingbeleid en beveiliging. En kosten kunnen verschuiven van API-gebruik naar device-ondersteuning, modeldistributie, monitoring en onderhoud.
Waarom schaal niet de enige ontwerpvariabele is
De AI-markt heeft lang een cloud-first reflex gehad: grotere modellen, meer compute, centrale inference en benchmarks als dominante meetlat. Die route heeft veel mogelijk gemaakt en blijft belangrijk. Grote modellen zijn vaak sterker in brede kennis, complexe redenering, lange contextvensters en taken die niet vooraf netjes zijn afgebakend. Voor veel teams is een cloud-LLM daarom nog steeds de snelste manier om te bouwen, te testen en te leren.
Maar schaal is niet dezelfde variabele als bruikbaarheid. Een model dat indrukwekkend scoort in algemene benchmarks kan ongeschikt zijn voor een toepassing die binnen milliseconden moet reageren, geen stabiele verbinding heeft of met gevoelige data werkt. Andersom kan een kleiner, hardwarebewust model voldoende zijn voor een smalle taak met duidelijke evaluatiecriteria. In dat geval wint het systeem niet omdat het ‘slimmer’ is in algemene zin, maar omdat het beter past bij de productconstraint.
Hardware-aware AI dwingt teams om vanaf het begin anders te denken. Niet alleen over promptkwaliteit of modelranking, maar over geheugengebruik, chipset, thermische limieten, batterijverbruik, foutgedrag, updatebaarheid en integratie met bestaande software. Dat voelt minder spectaculair dan een nieuw groot model, maar het is vaak precies waar productkwaliteit ontstaat. Funnel Adviseur ziet dezelfde les in automatisering breder terug: de beste oplossing is zelden de meest indrukwekkende losse tool; het is het systeem dat betrouwbaar past in het werkproces.
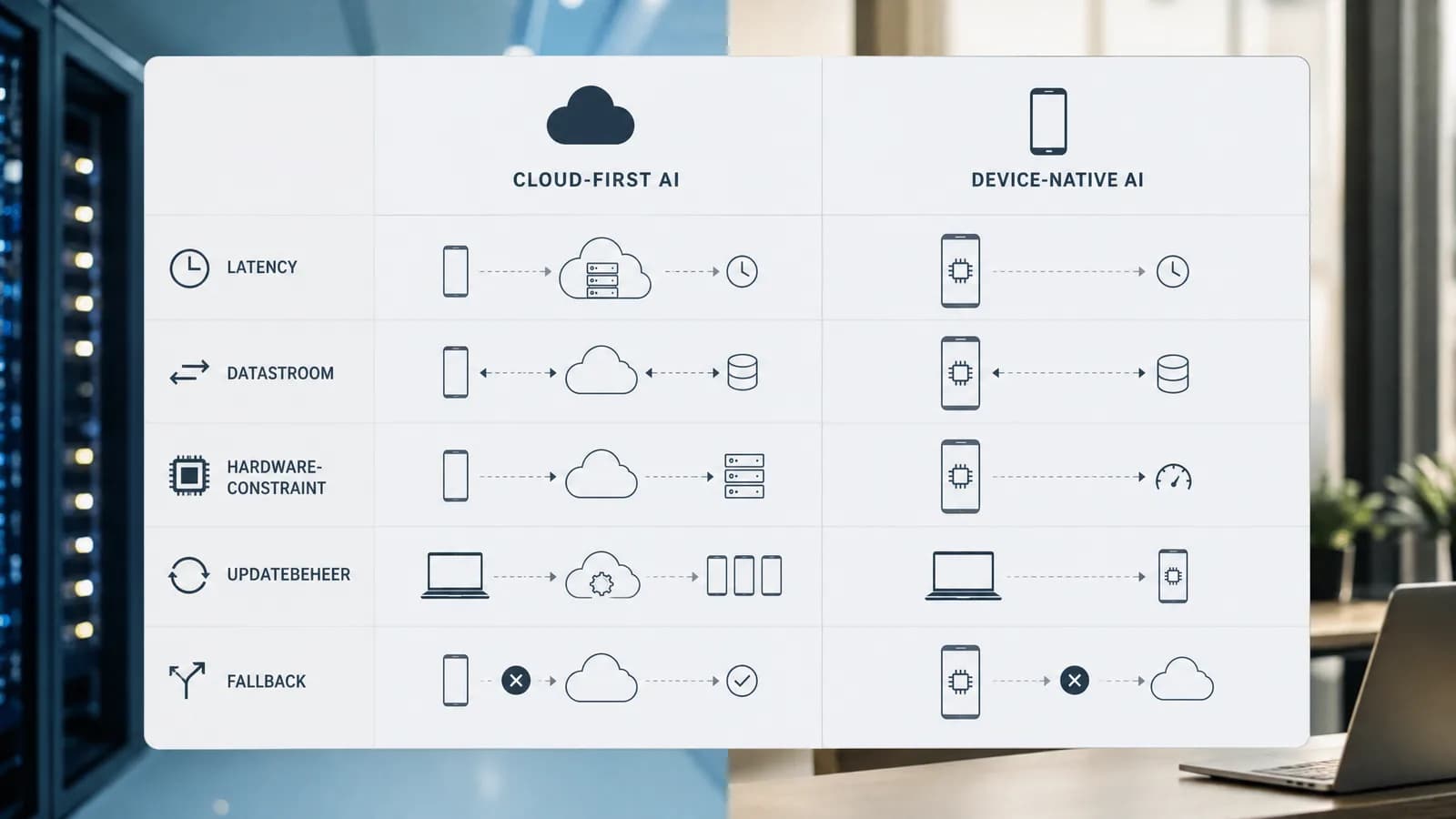
Wat device-native in de praktijk betekent
In de praktijk gaat device-native AI over toepassingen waarbij het apparaat zelf een actieve intelligentielaag krijgt. Denk aan een telefoon die persoonlijke assistentie lokaal voorbereidt, een laptop die documenten verwerkt zonder alles naar een externe dienst te sturen, een auto die bepaalde signalen snel interpreteert of een wearable die continue signalen analyseert met beperkte energie. Dit zijn categorieën waar latency, privacy, stroomverbruik en robuustheid zwaarder kunnen wegen dan maximale modelcapaciteit.
Belangrijk is dat ‘op het apparaat’ niet automatisch betekent dat alles lokaal moet gebeuren. Veel volwassen architecturen zullen hybride zijn. Een lokale laag kan eenvoudige classificatie, personalisatie, detectie of snelle interactie afhandelen. De cloud kan worden gebruikt voor zwaardere redenering, grote context, batchanalyse, modelverbetering of taken waarbij latency minder kritisch is. De kunst is om die grens expliciet te ontwerpen in plaats van toevallig te laten ontstaan.
Voor productteams is dit vooral een vraag over gebruikerservaring. Moet de gebruiker direct feedback krijgen, ook bij slechte verbinding? Is de input persoonlijk, bedrijfskritisch of gevoelig? Is de taak voorspelbaar genoeg om lokaal te testen? Kan een fout veilig worden opgevangen? Als het antwoord op die vragen scherp is, wordt de modelkeuze veel minder abstract. Dan vergelijk je niet ‘model A tegen model B’, maar ‘systeem A tegen systeem B onder echte gebruikscondities’.
De architectuurvraag: modelkeuze is infrastructuurkeuze
Een on-device model kiezen zonder infrastructuurontwerp is vragen om onderhoudsproblemen. Je moet weten hoe het model op apparaten terechtkomt, hoe updates worden uitgerold, hoe versies worden gecontroleerd, hoe fouten worden gemeld en wat er gebeurt als het model onvoldoende zeker is. Ook security verandert: bij cloud-inference beheer je vooral centrale toegang en datastromen; bij lokale inference moet je rekening houden met apparaten buiten je directe controle.
Open-weight modellen kunnen in dit landschap praktisch relevant zijn, omdat teams meer grip kunnen krijgen op experimenten, aanpassing en implementatie. Dat betekent niet dat open-weight altijd beter is. Je moet nog steeds kijken naar licentievoorwaarden, modelkwaliteit, safety, onderhoud, compatibiliteit met hardware en de vraag of je team de operationele verantwoordelijkheid aankan. Controle is pas waardevol als je ook de discipline hebt om die controle goed te gebruiken.
Daarom hoort device-native AI op de roadmap van zowel AI-engineering als productmanagement. Engineering beoordeelt latency, geheugen, energieverbruik en fouttypes. Product kijkt naar interactie, gebruikscontext en acceptabele risico’s. Legal en security beoordelen dataverwerking, toestemming en aanvalsvlak. Operations denkt na over support en incidenten. Als één van die disciplines ontbreekt, lijkt lokale AI in de demo vaak mooier dan in productie.
Wanneer on-device AI wél logisch is
On-device AI is het meest logisch bij een combinatie van duidelijke constraints. De eerste is latency: de toepassing moet merkbaar snel reageren of direct gekoppeld zijn aan een interface, sensor of veiligheidskritische workflow. De tweede is privacy of dataminimalisatie: de data is persoonlijk, commercieel gevoelig of simpelweg onnodig om centraal te verwerken. De derde is offline of instabiele verbinding: het product moet blijven werken zonder constante cloudtoegang.
Daarnaast helpt het als de taak afgebakend is. Lokale modellen zijn vaak het sterkst wanneer je precies weet wat ze moeten doen: intentie herkennen, signalen classificeren, korte tekst voorstellen, contextuele personalisatie uitvoeren, eenvoudige beslislogica ondersteunen of een eerste filter toepassen. Hoe opener de taak, hoe groter de kans dat een cloudmodel met meer context en capaciteit verstandiger is.
Een automotivecase maakt dit concreet zonder er een algemene belofte van te maken. In en rond voertuigen kunnen reactietijd, lokale sensordata, robuustheid en beperkte verbinding belangrijke ontwerpvariabelen zijn. Dat betekent niet dat alle intelligentie in een auto lokaal moet draaien. Het betekent wel dat sommige functies beter beoordeeld worden als edge-systeem dan als gewone API-call. Ook in commerce, B2B-portalen en persoonlijke assistenten kan dezelfde logica gelden: lokaal waar snelheid en context dichtbij de gebruiker belangrijk zijn, centraal waar analyse en schaal zwaarder wegen.
Wanneer je beter bij cloud-LLM’s blijft
Cloud-LLM’s blijven vaak de betere keuze wanneer de taak brede kennis, complexe redenering of grote contextvensters vraagt. Denk aan uitgebreide analyse van meerdere documenten, workflows die veel externe bronnen combineren, generatieve taken met hoge variatie of situaties waarin het model vaak moet worden vernieuwd. Centrale modellen zijn makkelijker te vervangen, te monitoren en te verbeteren zonder dat je afhankelijk bent van apparaatversies bij eindgebruikers.
Ook bij lage volumes kan cloud eenvoudiger zijn. Als een functie weinig wordt gebruikt, kan het operationeel zwaarder zijn om een lokaal model te distribueren en te onderhouden dan om gecontroleerd via een API te werken. On-device AI verschuift complexiteit. Je betaalt mogelijk minder per centrale inference, maar krijgt er vraagstukken voor terug rond compatibiliteit, modelupdates, support, foutdiagnose, storage en beveiliging op uiteenlopende apparaten.
Een andere reden om bij cloud te blijven is governance. Sommige teams denken dat lokale verwerking governance eenvoudiger maakt, maar dat hoeft niet. Je moet nog steeds weten welke data wordt verwerkt, welke output wordt gegenereerd, hoe gebruikers worden geïnformeerd, hoe fouten worden gelogd en hoe je misbruik voorkomt. On-device AI is geen shortcut rond beleid. Het is een andere uitvoeringslaag met eigen controles.

Praktisch evaluatiekader voor AI-teams
Begin niet met de vraag welk model populair is. Begin met de taak. Wat moet het systeem precies herkennen, voorspellen, samenvatten of voorstellen? Welke fout is acceptabel en welke fout niet? Hoe snel moet de respons zijn? Welke data mag het apparaat verlaten? Welke apparaten moet je ondersteunen? Pas als die vragen concreet zijn, heeft een modelvergelijking waarde.
Meet vervolgens onder apparaatcondities. Test latency op echte hardware, niet alleen op een krachtige ontwikkelmachine. Meet geheugengebruik, energieverbruik, opstarttijd, fouttypes, gedrag bij slechte verbinding en degradatie wanneer de context onvolledig is. Kijk niet alleen naar gemiddelde prestaties, maar ook naar randgevallen. Een model dat meestal goed werkt maar onvoorspelbaar faalt, kan in een lokale productervaring schadelijker zijn dan een iets beperkter model met duidelijker grenzen.
Ontwerp daarnaast een fallback. Wat gebeurt er als het lokale model onzeker is, de taak buiten scope valt of een apparaat te oud is? Stuur je door naar een cloudmodel, vraag je extra bevestiging van de gebruiker of beperk je de functie? Een goede hybride architectuur maakt die keuzes expliciet. Voor B2B-teams die AI in websites, portals of leadprocessen verwerken, sluit dit aan bij bredere automatiseringsprincipes: maak beslisregels zichtbaar, meetbaar en herstelbaar. Zie ook de AI-kennisbank van Funnel Adviseur en de pagina over B2B website automatisering voor bredere context rond AI in commerciële systemen.
Conclusie: vraag waar intelligentie hoort te draaien
Device-native AI is geen hype die cloud-AI overbodig maakt. Het is een serieus architectuurpad voor situaties waarin lokale context, snelheid, privacyverwachting, offline werking of apparaatinteractie zwaar wegen. De waarde zit niet in het label ‘on-device’, maar in de match tussen productconstraint en systeemontwerp.
Voor AI-teams betekent dit dat modelselectie volwassener moet worden. Benchmarks blijven nuttig, maar ze zijn onvoldoende. Je moet beoordelen hoe een model zich gedraagt op echte apparaten, binnen echte workflows en met echte foutkosten. Pas dan zie je of een kleiner, hardwarebewust model beter past dan een groter cloudmodel.
De nuchtere aanbeveling: begin smal. Kies één use-case met duidelijke latency-, privacy- of offline-eis. Definieer acceptatiecriteria. Test lokaal, test hybride en test cloud-first naast elkaar. Meet niet alleen outputkwaliteit, maar ook beheerbaarheid. Als on-device AI daarna wint, heb je een architectuurkeuze gemaakt in plaats van een trend gevolgd.



