De AI-agent is geen chatbot meer: waarom security een eigen threat model nodig heeft

De agent verandert het risicoprofiel
Veel teams behandelen AI-agents nog alsof het chatbots zijn met een iets langere actielijst. Dat is begrijpelijk, maar te beperkt. Een chatbot geeft tekst terug. Een agent kan, afhankelijk van de inrichting, code schrijven, een browser bedienen, interne informatie lezen, bestanden analyseren, tickets aanpassen of namens een gebruiker een vervolgactie starten. Op dat moment is het geen los taalmodel meer, maar een handelende softwarecomponent in je product- of bedrijfsproces.
Daarmee verschuift de kernvraag. Het gaat niet alleen meer om: geeft het model een goed antwoord? De vraag wordt: wat mag dit systeem zien, beslissen, proberen, opslaan en uitvoeren? Die verschuiving is precies waarom een AI-agent een eigen threat model nodig heeft. Niet omdat ieder agentproject gevaarlijk is, maar omdat de combinatie van model, context, tools, data en bevoegdheden een ander aanvalsvlak maakt dan een klassieke chatbot of SaaS-feature.
De nuchtere les is dus niet: stop met agents. De les is: behandel een agent als software die namens iemand kan handelen. Software met rechten, identiteit, logging, limieten en een terugvalpad. Wie alleen naar modelkwaliteit kijkt, mist de plek waar het echte productrisico vaak ontstaat: de koppeling tussen modeloutput en daadwerkelijke acties.
Waarom gewone cybersecurity belangrijk blijft, maar niet genoeg is
Klassieke cybersecurity blijft onmisbaar. Je wilt nog steeds veilige authenticatie, versleuteling waar nodig, toegangsbeheer, dependency management, monitoring en incidentrespons. Een agent vervangt die basis niet. Het probleem is dat agents extra risico’s introduceren via taal, context en toolgebruik. Een agent kan instructies krijgen uit een prompt, maar ook uit een document, webpagina, e-mail, ticket, codebestand of eerder geheugen. Niet al die tekst is betrouwbaar.
Dat maakt AI-security niet simpelweg ‘cybersecurity met AI erbovenop’. Een traditionele applicatie voert meestal vooraf geprogrammeerde stappen uit. Een agent interpreteert instructies, weegt context en kiest soms uit meerdere tools. Daardoor moet je niet alleen nadenken over wie toegang heeft tot het systeem, maar ook over welke informatie het systeem als instructie mag behandelen. Dat onderscheid is cruciaal.
Een praktisch threat model voor agents kijkt daarom naar vier lagen tegelijk: het model, de context die het model ziet, de tools die het model mag gebruiken en de acties die daaruit kunnen volgen. Als één laag te ruim is ingericht, kan een verder nette implementatie alsnog kwetsbaar worden. Een goed antwoord van het model is dan niet genoeg; het systeemgedrag moet begrensd zijn.
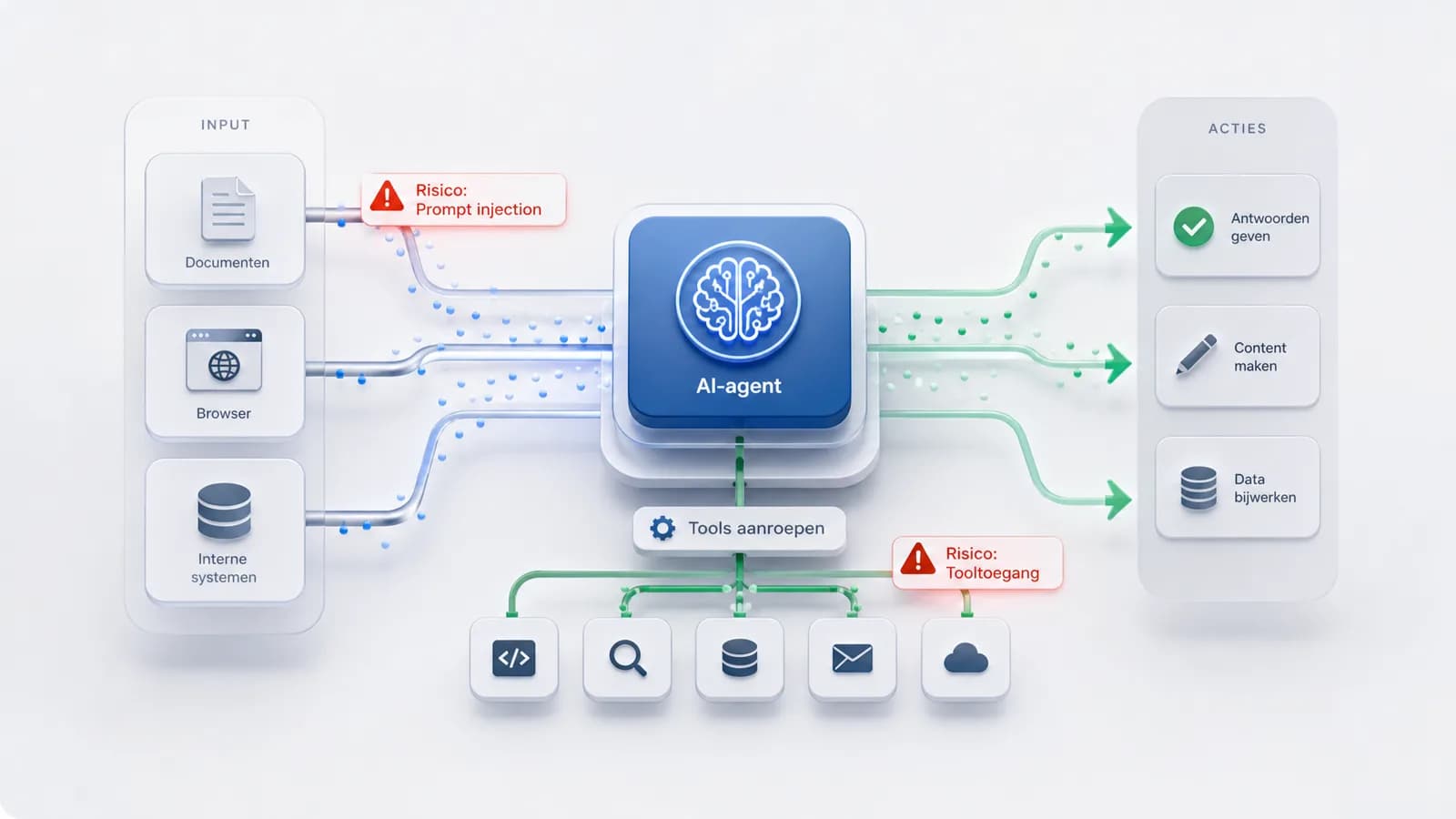
Prompt injection is een productprobleem
Prompt injection wordt vaak besproken alsof het alleen een modelprobleem is: kan het model een schadelijke of misleidende instructie negeren? Dat is te smal. Voor productteams is prompt injection vooral een ontwerpprobleem. Waar kan onbetrouwbare tekst het systeem binnenkomen? Welke tekst wordt gezien als informatie, en welke tekst als opdracht? Mag een agent instructies uit een externe webpagina opvolgen? Mag een document de agent beïnvloeden bij het kiezen van een tool?
Denk aan een agent die documenten samenvat, e-mails voorbereidt, tickets verwerkt, codebases analyseert of browserhandelingen uitvoert. In al die situaties kan de agent tekst tegenkomen die niet door je eigen team is geschreven. Die tekst kan informatief zijn, maar ook sturend. Het securitymodel moet daarom expliciet maken welke bronnen alleen gelezen mogen worden en welke bronnen instructies mogen geven. Zonder die scheiding wordt elke tekst in de context potentieel onderdeel van de besturing.
De meest praktische maatregel is niet één magische filterlaag. Het is een set ontwerpkeuzes: beperk wat de agent mag doen op basis van onbetrouwbare input, scheid systeeminstructies van externe inhoud, laat risicovolle acties bevestigen door een mens en test bewust met scenario’s waarin documenten of webpagina’s de agent proberen te sturen. Prompt injection hoort dus in de productreview, niet alleen in een modelbenchmark.
Agent-identiteit: namens wie handelt het systeem?
Zodra een agent acties uitvoert, moet je weten namens wie hij handelt. Gebruikt de agent de rechten van de ingelogde gebruiker? Werkt hij via een service-account? Heeft hij een eigen identiteit met afgebakende permissies? Dit lijkt een technisch detail, maar het bepaalt de schade die mogelijk is bij fouten, misbruik of verkeerde interpretaties.
Een agent met brede service-accountrechten is aantrekkelijk voor snelheid, maar riskant als hij meer kan dan nodig is. Een agent die volledig meeloopt op gebruikersrechten voelt veiliger, maar kan onduidelijk worden als acties automatisch plaatsvinden zonder expliciete bevestiging. Een eigen agent-identiteit kan helpen, mits rechten, logging en eigenaarschap goed zijn ingericht. De juiste keuze hangt af van de workflow, maar de vraag mag niet impliciet blijven.
Voor Funnel Adviseur-context betekent dit: ontwerp agents niet alleen vanuit de ideale customer journey of interne efficiëntie, maar ook vanuit verantwoordelijkheid. Wie keurde deze actie goed? Wie kan zien wat er is gebeurd? Wie kan een actie terugdraaien? En wie is eigenaar als de agent iets doet wat technisch toegestaan was, maar zakelijk ongewenst? Dat zijn geen remmende vragen; ze maken automatisering productierijp.
Tooltoegang en data: minder is meestal sterker
Een agent wordt pas nuttig wanneer hij tools en data kan gebruiken. Tegelijk zit daar het grootste verschil met een gewone chatbot. Een agent die alleen antwoord geeft, kan fout zitten. Een agent die een CRM bijwerkt, een pull request aanmaakt, een bestand verwijdert of een externe workflow start, kan directe gevolgen veroorzaken. Daarom moet tooltoegang zo specifiek mogelijk zijn.
Begin bij de minimale set: welke data heeft de agent echt nodig voor deze taak? Welke tools zijn noodzakelijk? Welke acties mogen automatisch, en welke acties vereisen bevestiging? Een agent die offertes voorbereidt, hoeft misschien wel gegevens te lezen en concepten te maken, maar niet zelfstandig definitieve contracten te versturen. Een agent die code analyseert, hoeft misschien suggesties te doen, maar niet zonder review te deployen.
Dataminimalisatie is hier niet alleen juridisch netjes; het is ook technisch verstandig. Hoe minder gevoelige data in de context staat, hoe kleiner het risico bij verkeerd gedrag. Hoe smaller de toolrechten, hoe kleiner de impact van een fout. En hoe duidelijker de grens tussen concept, aanbeveling en uitvoering, hoe beter gebruikers begrijpen wat ze aan de agent kunnen overlaten.

Red teaming vóór productie, niet na het incident
Agents vragen om testregimes die verder gaan dan normale happy-flow QA. Natuurlijk test je of de agent de beoogde taak goed uitvoert. Maar je moet ook testen hoe hij reageert op verwarrende, tegenstrijdige of sturende input. Wat gebeurt er als een document instructies bevat die botsen met de systeeminstructie? Wat doet de agent als een webpagina vraagt om gevoelige informatie te negeren of juist door te sturen? Wat gebeurt er als een tool faalt en de agent een omweg zoekt?
Automated red teaming kan hierbij een nuttige rol krijgen, vooral omdat handmatige testsets vaak te klein zijn voor alle varianten van taalgedrag. Dat betekent niet dat je menselijke review kunt schrappen. Het betekent wel dat teams systematischer kunnen zoeken naar zwakke plekken in prompts, toolkeuzes, contextscheiding en guardrails. Combineer dus geautomatiseerde aanvalsscenario’s met menselijke beoordeling van de zakelijke impact.
Belangrijk is dat red teaming niet alleen op het model wordt gedaan. Test de volledige keten: input, instructies, retrieval, tools, logging, permissies, gebruikersbevestiging en rollback. Een model kan een aanval herkennen, maar het product kan alsnog te veel rechten geven. Andersom kan een model soms onzeker zijn, terwijl goede guardrails voorkomen dat er schade ontstaat. Security zit in het systeem, niet in één laag.
Enterprise guardrails zijn adoptievoorwaarden
Voor teams die agents in een zakelijke omgeving willen inzetten, zijn guardrails geen cosmetische laag. Ze bepalen of de organisatie het systeem kan vertrouwen binnen concrete workflows. Goede guardrails beperken tooltoegang, scheiden gevoelige data, leggen acties vast, vragen bevestiging bij risicovolle stappen en maken escalatie naar mensen mogelijk. Dat klinkt minder spectaculair dan een autonome agent, maar het is meestal precies wat nodig is voor verantwoord productiegebruik.
Compliance en verzekerbaarheid worden bij AI-agents ook relevanter als gespreksonderwerp, vooral wanneer agents toegang krijgen tot klantdata, interne systemen of financiële processen. Het is verstandig om dit niet pas aan het einde van een pilot te bespreken. Betrek security, legal, operations en product vroeg genoeg om randvoorwaarden te vertalen naar ontwerpkeuzes. Welke logs zijn nodig? Welke data mag worden verwerkt? Welke acties moeten aantoonbaar door een mens zijn bevestigd?
Een houdbaar agentontwerp is daardoor vaak minder autonoom dan de demo. Dat is geen zwakte. Het is het verschil tussen een indrukwekkende proef en een betrouwbaar systeem. Zeker in B2B-omgevingen, waar automatisering onderdeel wordt van klantcontact, operations of interne besluitvorming, levert een beperkte maar controleerbare agent vaak meer waarde dan een brede agent zonder duidelijke remmen.
Checklist voor teams die AI-agents bouwen
Een praktisch startpunt is een checklist voordat je een agent koppelt aan echte data of echte acties. Eén: welke taak moet de agent precies uitvoeren, en welke taken vallen expliciet buiten scope? Twee: welke data mag de agent zien, en welke data moet buiten de context blijven? Drie: welke tools mag de agent gebruiken, met welke rechten en onder welke voorwaarden?
Vier: welke acties mogen automatisch worden uitgevoerd, en welke acties vragen menselijke bevestiging? Vijf: hoe wordt prompt injection getest vanuit documenten, browserinhoud, e-mails, tickets of andere tekstbronnen? Zes: hoe worden acties gelogd, zodat later zichtbaar is welke input, tool en beslissing tot een uitkomst leidde? Zeven: hoe kan een fout worden teruggedraaid of beperkt?
Acht: wie is eigenaar van het risico? Product, security, legal en operations hebben elk een ander perspectief. Als niemand expliciet eigenaar is, valt het risico tussen teams in. Negen: wanneer mag de agent niet antwoorden of niet handelen? Tien: hoe wordt het systeem opnieuw beoordeeld wanneer nieuwe tools, nieuwe databronnen of nieuwe workflows worden toegevoegd? Een agent is geen eenmalige feature; het risicoprofiel verandert mee met zijn koppelingen.
Wacht niet op het eerste incident om je model aan te passen
De belangrijkste stap is mentaal: zie een AI-agent niet als een slimmer tekstvak, maar als een actor binnen je softwarelandschap. Hij heeft input, context, rechten, tools, doelen en beperkingen nodig. Daarmee hoort hij thuis in architectuurreviews, securityreviews en productbeslissingen. Niet pas als er iets misgaat, maar voordat hij met echte bevoegdheden werkt.
Dat vraagt om nuchterheid. Niet elk agentproject heeft een zwaar enterprise securityprogramma nodig. Een interne conceptassistent zonder toolrechten vraagt om een ander niveau dan een agent die klantdata leest of systemen bijwerkt. Maar zodra een agent kan handelen, moet je de handelingsruimte ontwerpen. Minder rechten, betere logging, duidelijke bevestigingsmomenten en gerichte red teaming zijn geen vertraging; ze zijn onderdeel van productkwaliteit.
Voor AI-builders en CTO’s is dit de kern: modelkwaliteit blijft belangrijk, maar productierijpheid zit in de combinatie van model, tools, data en governance. Wie dat vanaf het begin meeneemt, kan agents veiligere taken geven en sneller leren waar autonomie echt waarde toevoegt. Wie het overslaat, bouwt vooral vertrouwen op een demo. En een demo is geen securitymodel.



