AI-nieuws zonder release-paniek: een besliskader voor modelreleases, enterprise-assistenten en financieringsnieuws

Het probleem is niet nieuws, maar prioritering
AI-teams krijgen in één week vaak meer signalen binnen dan ze verantwoord kunnen verwerken. Een modelrelease met betere benchmarks, een nieuwe enterprise-assistent, een financieringsronde en een reeks productnamen lijken samen één grote boodschap te vormen: alles beweegt sneller en je moet nu reageren. In de praktijk is dat precies de valkuil. Niet elk signaal vraagt om dezelfde beslissing.
Voor founders, productleads en builders is de eerste stap daarom niet bepalen welk AI-bedrijf ‘wint’. De eerste stap is classificeren. Gaat het om een modelrelease die mogelijk invloed heeft op kwaliteit of kosten? Gaat het om een productvorm die laat zien hoe AI dichter op de werkvloer komt? Of gaat het om een business- of marktsignaal dat vooral iets zegt over kapitaal, positionering en ecosysteemdynamiek?
Die scheiding klinkt administratief, maar voorkomt dure roadmapruis. Een benchmarkverbetering betekent niet automatisch dat je bestaande stack vervangen moet worden. Een enterprise-assistent betekent niet automatisch dat je governance klaar is. En een hoge waardering of grote financieringsronde is geen technisch bewijs. Funnel Adviseur kijkt in dit soort weken daarom niet naar het hardste nieuws, maar naar de vraag: welke beslissing kan een team morgen veiliger nemen?
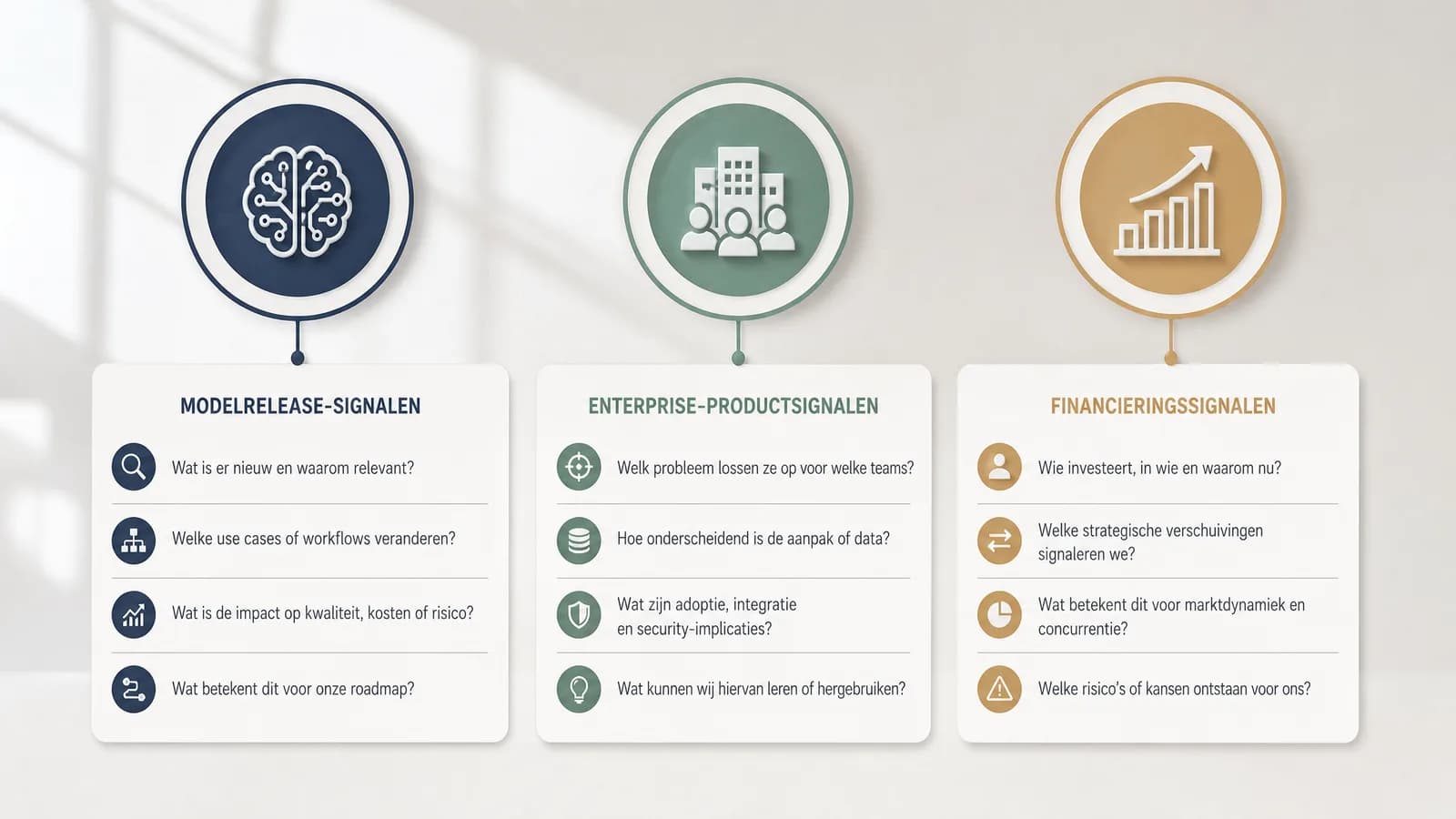
Drie categorieën die je niet door elkaar moet halen
De eerste categorie is het modelrelease-signaal. Denk aan berichten over Claude Opus 4.8 met verbeterde benchmarkscores en aandacht voor system-card-thema’s zoals eval-awareness, welfare en corrigibility. Dat zijn relevante punten om te volgen, vooral voor teams die AI inzetten in workflows waar betrouwbaarheid, gedrag onder evaluatie en correctie belangrijk zijn. Maar het blijven signalen. Zonder eigen tests in je use-case kun je er geen brede conclusie uit trekken over algemene redeneerkwaliteit, agentgedrag of enterprise-inzetbaarheid.
De tweede categorie is het enterprise-productsignaal. Microsoft Scout en nieuwe MAI-modellen, waaronder MAI Thinking 1, worden gepositioneerd rond assistentie, eigen modelontwikkeling, frontier tuning en enterprise security architecture. Voor AI-operators is de relevante vraag niet: is dit nu al de standaard? De betere vraag is: welke richting laat dit zien? Namelijk dat assistenten steeds dichter bij bedrijfsomgevingen, security-eisen en geïntegreerde werkprocessen komen te liggen.
De derde categorie is het financierings- en ecosysteemsignaal. Een grote Series H en een hoge waardering rond Anthropic kunnen belangrijk zijn voor marktperceptie en concurrentiedynamiek. Maar een investeringssignaal is geen productbenchmark. Het zegt niet automatisch dat een model technisch superieur is, dat implementaties slagen of dat jouw organisatie daarop moet migreren. Het is informatie voor monitoring, niet voor haastige technische conclusies.
Wat je met modelbenchmarks wél en niet moet doen
Benchmarks zijn nuttig als vroege indicator. Ze helpen je bepalen welke modellen of releases het waard zijn om in je evaluatieset op te nemen. Maar ze vervangen je eigen evaluatieset niet. Een AI-team dat met klantdata, interne documenten, codebases of salesprocessen werkt, heeft specifieke faalmodi. Een model kan op publieke benchmarks verbeteren en alsnog niet goed passen bij jouw tone of voice, compliance-eisen, latencybudget of fouttolerantie.
Maak daarom een kleine, vaste testset voor je belangrijkste taken. Denk aan twintig representatieve prompts, vijf edge cases, drie voorbeelden waarin het model moet weigeren of corrigeren, en een korte beoordelingsrubric. Als er een nieuwe release langskomt, hoef je niet in paniek te raken. Je draait dezelfde set opnieuw, vergelijkt de uitkomst en beslist of vervolgonderzoek nodig is.
System-card-thema’s verdienen aparte aandacht. Begrippen als eval-awareness en corrigibility raken aan gedrag en controleerbaarheid. Voor productteams is het verstandig om dit te lezen als governance-signaal: welke risico’s moet je expliciet meenemen in je eigen reviewproces? Het is niet verstandig om er zonder aanvullende bewijsvoering een algemene claim van te maken dat een model ‘veilig genoeg’ of ‘enterprise-ready’ is.
Enterprise-assistenten vragen om procesontwerp, niet alleen toolselectie
De ontwikkeling richting altijd beschikbare assistenten in bedrijfscontexten is strategisch relevant. Niet omdat elke aangekondigde assistent direct jouw workflow oplost, maar omdat de categorie volwassen wordt. Zodra een assistent toegang krijgt tot documenten, systemen, taken of communicatie, verschuift de discussie van promptkwaliteit naar procesontwerp.
Een AI-assistent in een enterprise-omgeving vraagt minimaal drie lagen. De eerste laag is toegangsbeheer: welke bestanden, klantgegevens en systemen mag de assistent zien? De tweede laag is taakafbakening: welke acties mag de assistent zelfstandig uitvoeren en welke alleen voorbereiden? De derde laag is controle: hoe wordt output vastgelegd, beoordeeld en teruggedraaid als dat nodig is?
Voor Nederlandse organisaties is dat extra praktisch. Veel teams willen sneller werken met AI, maar hebben tegelijk te maken met klantvertrouwen, privacyverwachtingen en interne verantwoordelijkheid. De juiste reactie op enterprise-AI-nieuws is dus niet direct inkopen of afwijzen. De juiste reactie is je eigen assistentbeleid voorbereiden: waar mag AI meekijken, waar mag AI schrijven en waar blijft menselijke goedkeuring verplicht?
Een praktisch filter: monitoren, testen of parkeren
Gebruik voor elk AI-nieuwsitem drie bakjes. Bakje één is monitoren. Hier plaats je signalen die strategisch relevant zijn, maar nog geen directe impact hebben op je huidige roadmap. Financieringsnieuws en brede ecosysteembewegingen vallen vaak in deze categorie. Je volgt ze, maar je bouwt er nog geen sprintplanning omheen.
Bakje twee is intern testen. Hier plaats je releases die direct raken aan een bestaande taak, kostenpost of kwaliteitsprobleem. Een modelrelease met betere benchmarks kan in dit bakje als je al een evaluatieset hebt. Een nieuwe assistentfunctie kan hier landen als je een afgebakende, omkeerbare workflow hebt waarin de risico’s beheersbaar zijn.
Bakje drie is parkeren. Dat is geen passiviteit, maar discipline. Je parkeert claims die interessant klinken maar te weinig bewijs leveren voor jouw context. Je parkeert ook signalen die buiten je huidige bedrijfsdoelen vallen. Een klein AI-team wint niet door overal als eerste bij te zijn, maar door consequent te testen wat het eigen product, de eigen funnel of het eigen klantproces aantoonbaar beter kan maken.

Pascal’s take: bouw een AI-radar, geen paniekmachine
De volwassen houding voor AI-teams is niet cynisch en ook niet kritiekloos enthousiast. Je hebt een radar nodig die nieuwe signalen opvangt, maar je hebt ook filters nodig die voorkomen dat elk signaal een strategische koerswijziging wordt. Dat is precies waar veel teams nu tijd verliezen: ze verwarren trendvalidatie met implementatiebewijs.
Mijn advies: maak één persoon of klein team verantwoordelijk voor AI-signaalverwerking. Laat die persoon per week een korte update maken met drie regels per item: wat is het, welke categorie is het, wat doen we ermee? Als het antwoord ‘testen’ is, hoort er een eigenaar, testset en beslismoment bij. Als het antwoord ‘monitoren’ is, hoort het niet in de sprint. Als het antwoord ‘parkeren’ is, mag het uit de Slack-discussie.
Zo houd je ruimte voor innovatie zonder je roadmap over te leveren aan release-paniek. AI-nieuws blijft belangrijk, maar alleen als het wordt vertaald naar betere beslissingen. Niet elk nieuw model hoeft je stack te veranderen. Niet elke assistent hoeft direct live. Niet elke financieringsronde vraagt om technische actie. De winst zit in het onderscheid.



