Eigen AI-geheugen bouwen: context wordt belangrijker dan de chatbot

Kernantwoord: AI-geheugen is geen gimmick maar een ontwerpkeuze
Veel AI-teams hebben de afgelopen periode vooral geleerd hoe krachtig losse prompts kunnen zijn. Je vraagt om een analyse, een voorstel, een samenvatting of een stuk code en krijgt direct bruikbare output terug. Dat is waardevol, maar het heeft een duidelijke grens: de context verdwijnt vaak net zo snel als hij is opgebouwd. De volgende sessie weet niet vanzelf welke keuzes eerder zijn gemaakt, welke klantafspraken gevoelig liggen, welke tone-of-voice intern is goedgekeurd of welke procesregel absoluut niet mag worden overtreden.
Daarom wordt AI-geheugen een belangrijker ontwerpvraagstuk. Niet als magisch geheugen dat alles bewaart, maar als een beheerde contextlaag. Die laag bevat informatie die de AI niet telkens opnieuw hoeft te raden: projectdoelen, voorkeuren, beslisregels, klantcontext, productkeuzes, documentatie en eerdere besluiten. Het model levert redeneerkracht, maar de geheugenlaag bepaalt welke context betrouwbaar beschikbaar is op het moment dat er gewerkt wordt.
Voor Funnel Adviseur is dit vooral interessant vanuit procesontwerp. De vraag is niet: welke chatbot wint deze maand? De betere vraag is: welke context wil je als organisatie zelf beheren, zodat je niet afhankelijk wordt van losse gesprekken en individuele promptgewoontes? Als AI onderdeel wordt van dagelijkse operatie, verkoop, support, productontwikkeling of marketing, dan is geheugen geen extraatje. Het is de laag die bepaalt of AI-werk reproduceerbaar, controleerbaar en overdraagbaar wordt.
Dat betekent niet dat elk bedrijf direct een volledig agentplatform moet bouwen. Sterker nog: dat is vaak te groot en te riskant als eerste stap. Begin kleiner. Kies één workflow waar contextverlies zichtbaar pijn doet. Denk aan offertevoorbereiding, klantonderzoek, contentbriefings, supporttriage, productdocumentatie of interne besluitvoorbereiding. Ontwerp daar eerst wat de AI moet onthouden, wat hij juist moet vergeten en waar een mens expliciet akkoord moet geven.
Van losse prompt naar intent loop
Een losse prompt is een opdracht. Een intent loop is een werkrelatie. Bij een losse prompt geef je instructies, beoordeel je het antwoord en begin je de volgende keer vaak opnieuw. Bij een intent loop geef je richting, waarna de AI context verzamelt, een voorstel doet, ontbrekende informatie signaleert en wacht op bevestiging voordat hij verdergaat. De kern is niet meer alleen output genereren, maar samen naar een gecontroleerde vervolgstap bewegen.
Die verschuiving is belangrijk omdat agents anders te snel worden behandeld alsof ze autonome medewerkers zijn. In de praktijk is dat meestal niet verstandig. Een agent kan helpen met voorbereiden, structureren, controleren en concepten maken, maar hij moet binnen duidelijke stopregels werken. Wanneer mag hij alleen adviseren? Wanneer mag hij een concept klaarzetten? Wanneer mag hij gegevens combineren? Wanneer mag hij niets doen zonder menselijke goedkeuring? Dat zijn geen technische details aan het einde van het project; het zijn ontwerpkeuzes aan het begin.
Een goede intent loop bevat minimaal vier onderdelen. Eerst is er de intentie: wat probeert de gebruiker of het team te bereiken? Daarna komt contextselectie: welke informatie is relevant en betrouwbaar genoeg voor deze taak? Vervolgens komt het agentvoorstel: wat stelt het systeem voor, inclusief onzekerheden of ontbrekende informatie? Pas daarna volgt de menselijke beslissing: doorgaan, aanpassen, stoppen of escaleren. Juist die expliciete ja maakt het verschil tussen behulpzame automatisering en onduidelijke autonomie.
Voor AI-professionals klinkt dit misschien minder spectaculair dan volledig zelfstandige agents, maar het is in organisaties vaak nuttiger. De meeste schade ontstaat niet doordat AI geen antwoord kan geven, maar doordat het antwoord buiten de juiste context wordt gebruikt. Een intent loop dwingt het systeem om niet alleen slim te reageren, maar ook zichtbaar te maken waarom een vervolgstap logisch lijkt en waar nog menselijke beoordeling nodig is.
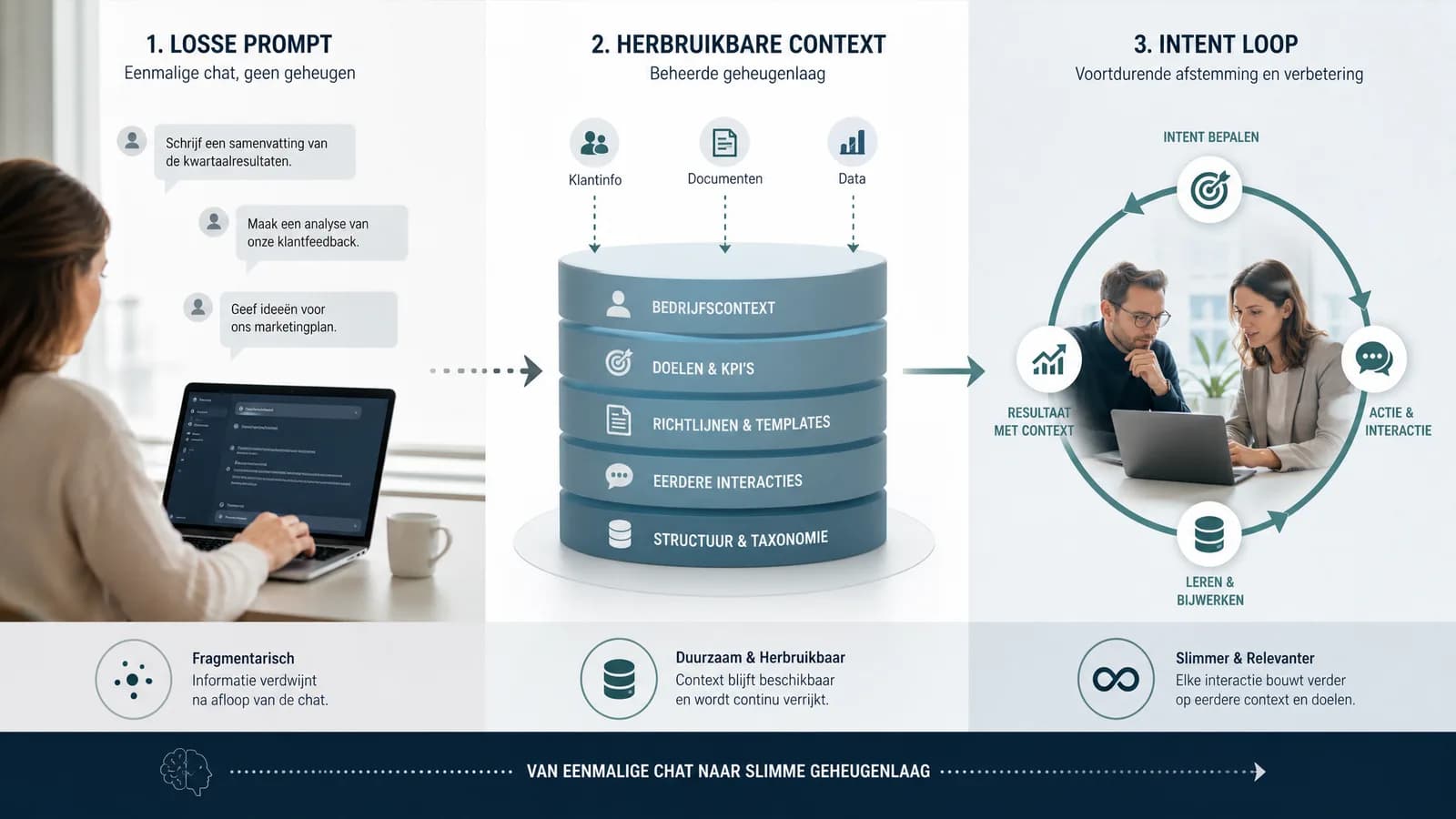
Waarom geheugenbezit strategischer is dan toolkeuze
AI-modellen zullen blijven veranderen. Vandaag gebruikt een team model A, morgen model B en volgende maand een combinatie van gespecialiseerde modellen. Dat is normaal. Maar als bij elke wissel ook alle context, voorkeuren en werkafspraken opnieuw moeten worden opgebouwd, blijft AI-adoptie oppervlakkig. De echte waarde zit dan niet in de tool, maar in het organisatiegeheugen dat boven of naast de tool wordt beheerd.
Geheugenbezit betekent niet dat alle data lokaal moet staan of dat elk team zelf complexe infrastructuur moet bouwen. Het betekent dat je bewust bepaalt welke context van jou is, hoe die wordt onderhouden en onder welke voorwaarden een AI-systeem die context mag gebruiken. Voor een productteam kan dat gaan om roadmapkeuzes en klantinzichten. Voor marketing om positionering, tone-of-voice en campagnehistorie. Voor sales om kwalificatiecriteria en terugkerende bezwaren. Voor operations om procesregels, uitzonderingen en escalatiepaden.
Zonder zo'n contextlaag ontstaat lock-in op een minder zichtbare manier. Niet alleen omdat een tool bepaalde data opslaat, maar omdat medewerkers leren werken in verspreide chats die nauwelijks overdraagbaar zijn. De waarde zit dan in persoonlijke promptgeschiedenis in plaats van in gedeelde proceskennis. Dat maakt opschalen moeilijk. Nieuwe collega’s moeten het wiel opnieuw uitvinden, managers kunnen kwaliteit lastig beoordelen en verbeteringen blijven hangen bij individuele power users.
Voor B2B-processen is dit extra relevant. Daar draait werk zelden om één losse tekst of één losse analyse. Het gaat om opvolging, bewijsvoering, timing, klantafspraken en interne verantwoordelijkheid. Wie AI wil inzetten in commerciële of operationele processen, moet dus niet alleen vragen welke output een model kan maken, maar ook welke context het mag meenemen. In die zin ligt er een directe link met bredere procesautomatisering, zoals Funnel Adviseur die benadert bij AI en automatisering voor B2B-processen.
Praktisch startpunt voor AI-teams
Een goed begin is niet: bouw een persoonlijke agent die alles kan. Een beter begin is: kies één workflow waarin contextverlies meetbaar irritant is. Bijvoorbeeld het voorbereiden van klantgesprekken, het maken van technische projectbriefings, het beantwoorden van terugkerende supportvragen of het opstellen van interne beslisnotities. Hoe smaller de eerste workflow, hoe makkelijker het wordt om geheugen, permissies en controlepunten scherp te ontwerpen.
Maak vervolgens een contextinventaris. Welke informatie heeft de AI nodig om beter werk te leveren? Welke informatie is gevoelig, verouderd of alleen bruikbaar met nuance? Welke bronnen zijn leidend als documenten elkaar tegenspreken? Welke gegevens mogen tijdelijk worden gebruikt, maar niet structureel worden onthouden? Deze vragen lijken administratief, maar ze bepalen direct de kwaliteit van de AI-output. Slechte context leidt tot overtuigend klinkende ruis.
Daarna ontwerp je de actieniveaus. Niveau één is adviseren: de AI analyseert en geeft opties. Niveau twee is voorbereiden: de AI maakt concepten, checklists of samenvattingen. Niveau drie is klaarzetten: de AI vult een taak voor, maar verzendt of wijzigt nog niets. Niveau vier is uitvoeren: de AI doet daadwerkelijk iets in een systeem. Voor veel organisaties hoort niveau vier voorlopig beperkt te blijven tot lage-risicotaken met duidelijke logging en herstelmogelijkheden.
Leg per niveau vast wanneer menselijke goedkeuring nodig is. Niet in vage termen zoals 'bij belangrijke zaken', maar concreet. Bijvoorbeeld: altijd goedkeuring bij externe communicatie, prijsinformatie, juridische formuleringen, dataverwijdering, klantstatuswijzigingen of wijzigingen in brondata. Zo ontstaat een agent die niet alleen helpt, maar ook weet waar zijn grens ligt.
Tot slot: behandel prompts niet als losse trucjes, maar als procesonderdelen. Een goede prompt beschrijft rol, doel, context, beperkingen en outputvorm. Een goede geheugenlaag zorgt dat een deel daarvan niet telkens handmatig hoeft te worden herhaald. De combinatie van beide maakt AI-werk stabieler. Meer praktische verdieping over dit soort procesmatige AI-toepassingen past goed in een bredere kennisbankaanpak, omdat het niet om hype gaat maar om herhaalbare werkwijzen.

Governance zonder het experiment dood te maken
Governance rond AI-geheugen hoeft innovatie niet te blokkeren. Het tegenovergestelde is vaak waar: heldere regels maken experimenten veiliger en sneller te evalueren. Als niemand weet wat de AI mag onthouden, welke bronnen leidend zijn of wanneer goedkeuring verplicht is, wordt elk experiment politiek en risicovol. Als die kaders wel duidelijk zijn, kunnen teams binnen een veilige speelruimte leren.
Begin met dataminimalisatie. Laat een AI-systeem niet alles onthouden omdat het technisch kan. Vraag per veld of per contexttype: draagt dit aantoonbaar bij aan betere beslissingen of betere output? Zo niet, dan hoort het niet in het geheugen. Dit is praktisch, niet alleen juridisch. Hoe meer irrelevante context wordt opgeslagen, hoe groter de kans dat de agent verkeerde verbanden legt of oude informatie blijft hergebruiken.
Gebruik daarnaast logboeken en reviewmomenten. Welke context gebruikte de AI? Welke aanbeveling deed hij? Waar corrigeerde de mens? Welke informatie bleek nuttig en welke juist misleidend? Die feedback maakt van AI-geheugen een leersysteem. Het geheugen wordt dan niet alleen een opslagplek, maar een instrument om werkafspraken te verbeteren.
Een volwassen aanpak accepteert dat geheugen ook onderhoud nodig heeft. Projecten veranderen, klanten veranderen, positionering verandert en interne regels veranderen. Als het geheugen niet wordt opgeschoond, groeit het risico dat oude aannames nieuwe beslissingen kleuren. Plan daarom periodieke checks: welke context is nog actueel, welke mag weg en welke moet scherper worden geformuleerd?
De belangrijkste nuance: eigen AI-geheugen is geen doel op zich. Het is nuttig wanneer het helpt om betere samenwerking tussen mens en AI te ontwerpen. Voor sommige taken blijft een losse prompt voldoende. Voor terugkerende, contextgevoelige en proceskritische taken wordt een geheugen- en intentielaag steeds logischer. Begin klein, hou de menselijke ja expliciet en bouw pas verder wanneer de workflow aantoonbaar duidelijker wordt.
Wat Funnel Adviseur hiermee zou doen
Vanuit Funnel Adviseur zou ik AI-geheugen niet starten als technisch project, maar als funnel- en procesvraag. Waar lekt context weg? Waar moeten medewerkers informatie steeds opnieuw uitleggen? Waar ontstaan kwaliteitsverschillen tussen ervaren en nieuwe teamleden? Waar worden AI-antwoorden gebruikt zonder dat duidelijk is welke aannames erin zitten? Die plekken zijn vaak betere startpunten dan algemene brainstorms over agents.
Een praktisch traject zou beginnen met één klantreis of interne workflow. Daarna worden contextbronnen, beslisregels, outputmomenten en goedkeuringspunten in kaart gebracht. Pas dan kies je tooling. Zo voorkom je dat een organisatie een agent bouwt rond toevallige toolmogelijkheden, terwijl de echte behoefte ligt in duidelijker contextbeheer en betere overdracht.
Voor AI-teams is de kern dus niet dat je alles zelf moet bouwen. De kern is dat je bewust eigenaar wordt van de context die je AI-werk waardevol maakt. Intelligentie kun je inkopen, wisselen of combineren. Je geheugenlaag, je intenties en je menselijke controlepunten vormen de basis waarop die intelligentie bruikbaar wordt in echte processen.



