Xiaomi’s MiMo-modellen: wat AI-teams hiervan moeten leren

De kern: niet juichen om een ranglijst, wel opletten op het signaal
Xiaomi’s MiMo-modellen zijn interessant, maar niet om de reden die in veel AI-discussies het snelst aandacht krijgt. De veilige conclusie is niet dat een telefoon-, appliance- en EV-bedrijf ineens bewezen beter is dan de bekende frontierlabs. De relevante conclusie is nuchterder: een product- en hardwarebedrijf positioneert zich zichtbaar met een reeks open-source AI-publicaties en modelvarianten. Voor AI-teams is dat een marktsignaal.
Dat verschil is belangrijk. In AI wordt een modelrelease snel vertaald naar winnaar-verliezer-taal: wie staat bovenaan, wie is ingehaald, welk lab is nu leidend? Voor teams die echte producten bouwen, is die framing meestal te smal. De vraag is niet alleen welk model vandaag het meeste aandacht krijgt. De vraag is welke partijen structureel modelcapaciteit opbouwen, welke ecosystemen ontstaan en welke releases op termijn bruikbaar kunnen worden in eigen workflows.
MiMo verdient daarom een plek op de modelradar, niet automatisch in de productiestack. Dat is precies het onderscheid dat volwassen AI-teams moeten maken. Signaleren is iets anders dan adopteren. Een nieuwe modelreeks kan strategisch relevant zijn, terwijl de praktische inzetbaarheid nog volledig moet worden getoetst.
Wat rond MiMo concreet opvalt
Rond Xiaomi’s AI-activiteiten worden meerdere MiMo-gerelateerde lijnen genoemd, waaronder MiMo, MiMo-Embodied, HySparse, MiMo Audio, MiMo VL en MiMo V2 Flash. Alleen al die breedte is relevant. Het gaat niet om één losse taalmodelclaim, maar om een cluster van modelnamen dat wijst op interesse in meerdere AI-richtingen: tekst, audio, vision-language en embodied AI.
Daarmee ontstaat een ander beeld dan bij een puur softwarematig modelproject. Een bedrijf dat al actief is in consumentenelektronica, apparaten en elektrische voertuigen heeft een logische reden om verder te kijken dan chatinterfaces. AI-capaciteit kan onderdeel worden van productplatformen, apparaten, assistenten, interfaces en mogelijk fysieke omgevingen. Dat maakt de beweging relevant voor AI-architecten, productteams en technische beslissers.
Tegelijk moeten we scherp blijven: de aanwezigheid van modelnamen en papers zegt nog niet dat de modellen in jouw context sterk presteren. Het zegt ook niet automatisch iets over betrouwbaarheid, latency, kosten, communityvolwassenheid of enterprise-inzetbaarheid. Die beoordeling begint pas nadat je primaire materialen, licentievoorwaarden, modelgewichten, benchmarkopzet en implementatiepad hebt gecontroleerd.
Waarom AI-teams verder moeten kijken dan de bekende labs
Veel modelwatchlists zijn impliciet gebouwd rond een handvol bekende AI-labs. Dat is begrijpelijk, want die partijen zetten vaak de toon in publieke benchmarks, tooling en ontwikkelaarservaring. Maar als AI-capaciteit steeds meer onderdeel wordt van productplatformen, is zo’n smalle watchlist kwetsbaar. Je mist dan signalen van bedrijven die AI niet alleen als modelproduct zien, maar als laag in hardware, software en diensten.
Voor AI-teams is de praktische verschuiving deze: modelstrategie wordt minder exclusief een labwedstrijd en meer een ecosysteemvraag. Wie heeft distributie? Wie heeft hardwarekanalen? Wie heeft ontwikkelaars nodig? Wie kan modellen koppelen aan bestaande producten? Wie publiceert open-source varianten die door de community kunnen worden getest, aangepast of vergeleken?
Dat betekent niet dat elk productbedrijf ineens een kernleverancier voor je AI-stack wordt. Het betekent wel dat je periodieke modelscouting breder moet zijn dan de usual suspects. Een goede modelradar bevat frontiermodellen, gespecialiseerde open-source modellen, regionale spelers, researchprojecten en modelreeksen van bedrijven die vanuit hardware of productplatformen komen.
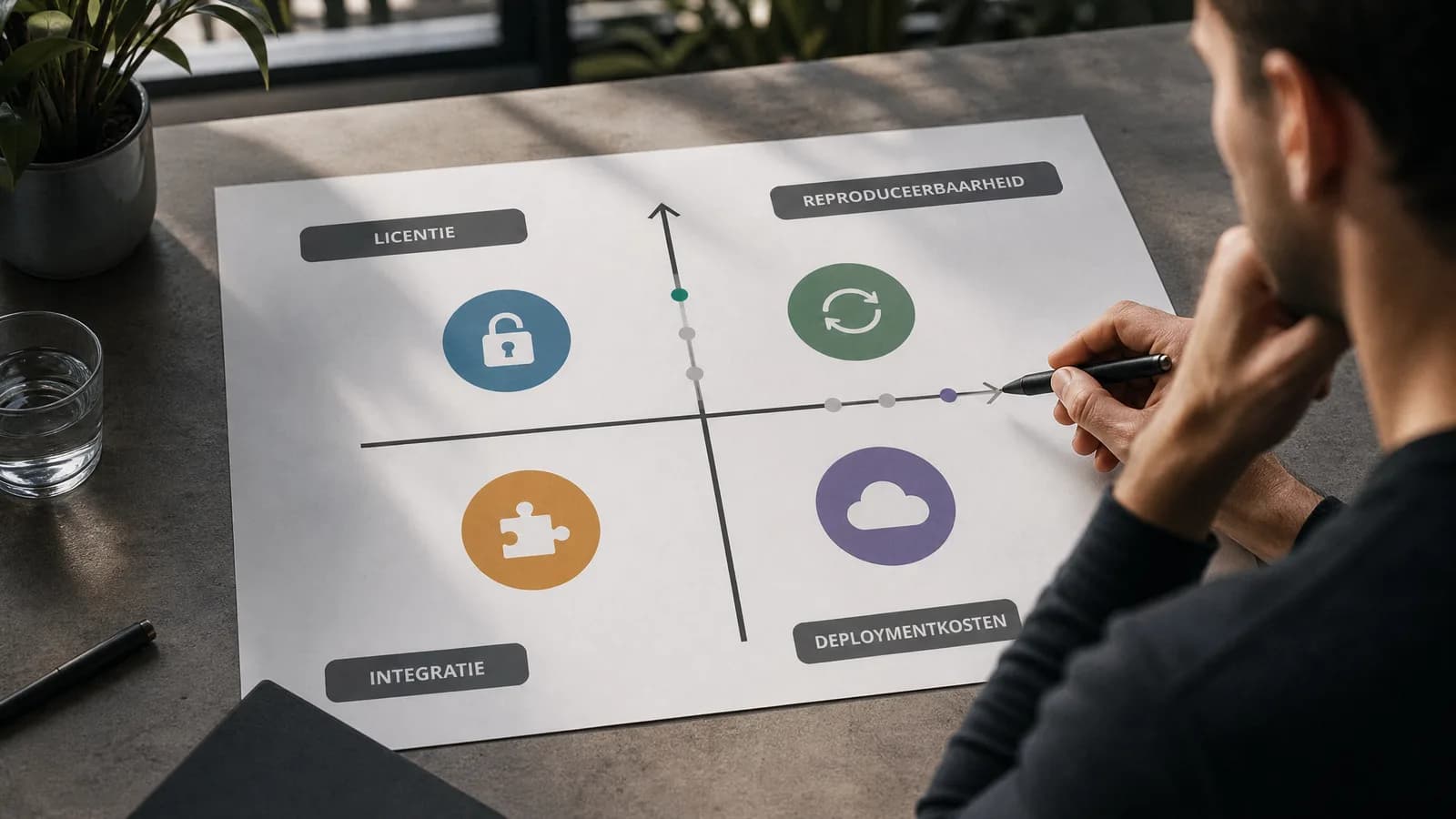
De beoordelingslens: van hype naar implementatie
De eerste stap is taaldiscipline. Vermijd interne conclusies als ‘dit model heeft de markt ingehaald’ zolang je dat niet zelf kunt onderbouwen. Gebruik liever categorieën zoals ‘monitoren’, ‘technisch verkennen’, ‘prototypewaardig’ of ‘nog niet relevant’. Daarmee voorkom je dat een enthousiaste release direct verandert in een roadmapbesluit.
De tweede stap is licentiecontrole. Open-source is geen uniforme categorie. Voor commerciële toepassing moet je weten wat wel en niet mag, welke beperkingen gelden, of afgeleide werken mogelijk zijn en of de licentie past bij jouw klantcontext. Zeker bij bureaus, SaaS-teams en bedrijven met gevoelige data is dit geen juridische bijzaak, maar een go/no-go-factor.
De derde stap is reproduceerbaarheid. Kijk niet alleen naar een leaderboardscore of samenvatting. Kun je de benchmarkopzet begrijpen? Zijn de testsets relevant voor jouw use-case? Is er informatie over evaluatiemethode, modelgrootte, contextvenster, instructiegedrag en fouttypes? Een model kan indrukwekkend lijken en alsnog slecht passen bij jouw workflow.
De vierde stap is operationele bruikbaarheid. Voor productie tellen latency, hostingopties, hardwarebehoefte, monitoring, fallbacklogica, promptgedrag, security en onderhoud zwaarder dan een eenmalige demo. Een model dat lokaal of goedkoop draait kan aantrekkelijk zijn, maar alleen als de outputkwaliteit, stabiliteit en beheerslast passen bij het proces dat je automatiseert.

Wat dit betekent voor productteams en AI-bouwers
Voor productteams is MiMo vooral een reminder dat AI-roadmaps niet losstaan van platformstrategie. Als een bedrijf meerdere modaliteiten onderzoekt, kan dat op termijn invloed hebben op interfaces, apparaatinteractie en multimodale workflows. Dat is relevant wanneer je producten bouwt waarin tekst, spraak, beeld of sensorische context samenkomen.
Voor AI-bouwers is de directe actie kleiner en concreter: voeg dit soort modelreeksen toe aan je watchlist, maar geef ze een status. Bijvoorbeeld: ‘signaleren’, ‘licentie checken’, ‘paper lezen’, ‘kleine evaluatie draaien’, ‘nog niet testen’. Zo voorkom je dat elk nieuw model dezelfde hoeveelheid aandacht opeist.
Voor teams die klanten adviseren, is dit ook een communicatievraag. Je hoeft niet elk nieuw model aan klanten te presenteren. Je moet wel kunnen uitleggen waarom je bepaalde ontwikkelingen volgt. De professionele boodschap is: we kijken breder dan de bekende merken, maar we nemen pas beslissingen na technische en operationele validatie.
Pascal’s conclusie: behandel MiMo als scoutingmateriaal
De waarde van Xiaomi’s MiMo-lijn zit op dit moment vooral in het signaal. Een bedrijf buiten de klassieke AI-labcategorie beweegt zichtbaar richting een bredere AI-modelstack. Dat past bij een markt waarin modelontwikkeling, hardware, productplatformen en open-source distributie dichter naar elkaar toe groeien.
Mijn advies aan AI-teams: maak hier geen machtswisselingsverhaal van. Gebruik het als aanleiding om je modelradar te verbeteren. Zet MiMo en vergelijkbare releases in een gestructureerd scoutingproces. Controleer licentie, benchmarks, modelgewichten, deploymentpad en communityactiviteit voordat je er tijd in investeert.
De teams die hier het meeste voordeel uit halen, zijn niet de teams die het snelst roepen dat een nieuw model alles verandert. Het zijn de teams die vroeg signaleren, rustig toetsen en pas daarna gericht experimenteren. Dat is minder spectaculair, maar veel betrouwbaarder voor echte AI-producten en automatiseringsprojecten.



